
A gentle introduction to how we use Topic Modeling to analyze Twitter data.
A Gentle Intro to Topic Modeling

One method that we’re using to analyze Canada Reads data is by topic modeling our Twitter data (and eventually transcripts of Canada Reads, news articles about Canada Reads, and the books themselves) in order to identify common themes that emerge.
Topic Modeling is a way of discover (or ‘articulating’ — this is up for debate) the latent ‘themes’ that constitute a collection of texts. Put (not so) simply, it’s a way of trying to understand the common topics or themes that can be identified in a collection of documents. If, for instance, we took all the articles in a newspaper for a year, took them out of their sections and placed them, out of order, into a topic modeling algorithm, we would expect that the algorithm would group articles from the same sections (Business, Sports, Arts, …) together. These would be the ‘topics’ that emerge from the collection of articles that constitute a newspaper over the span of the year. Topic modeling is, in this sense, a form of ‘distant reading’ — different from the notions of close reading we typically practice in literary studies: rather than trying to unpack the deep meaning of a small number of texts, distant reading attempts to identify broad patterns across a large number of texts.
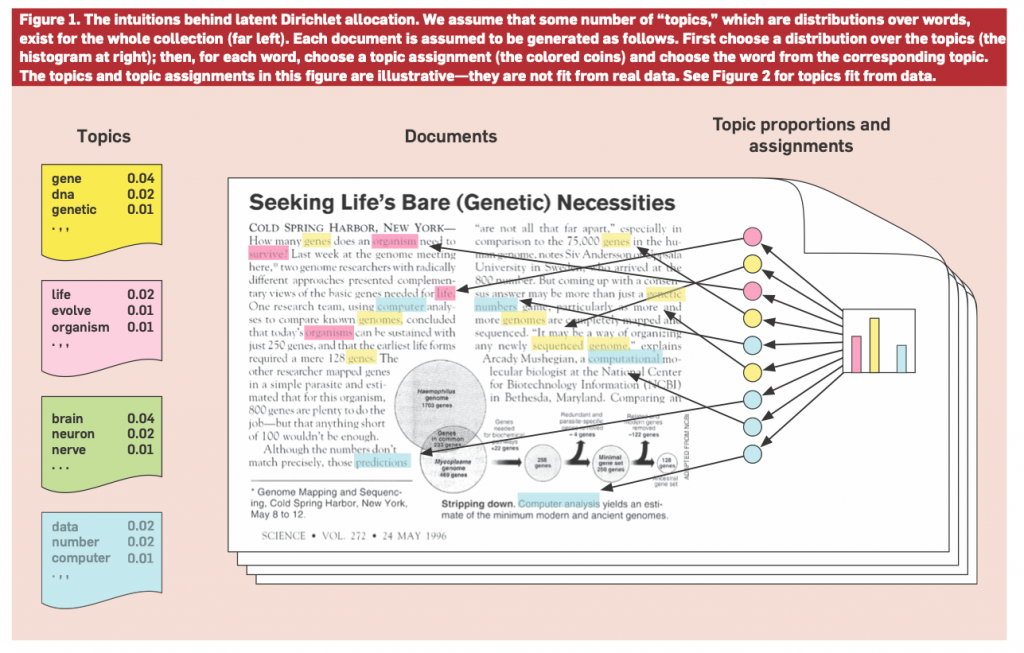
For a technical introduction to Topic Models see David Blei’s “Probabilistic Topic Models.”For a slightly more gentle introduction, see Paul Barrett’s article on the subject in Canadian Literature. Needless to say, topic modeling is controversial and not without its limits; part of our goal is to explore those limits and understand whether its actually a useful tool for analyzing public discussion in this way.
There are (at least) two controversial aspects of topic modeling. First, topic models are self-directed algorithms: we don’t tell the topic modeling algorithm what to look for: we give it the data, set a number of parameters, and then try to interpret the results. Second, one of the parameters that we set is the number of topics: choosing this number has a significant effect on the number of results that the algorithm will produce. So to use our newspaper example, if we choose number of topics = 1 our results would be so general that they couldn’t be meaningfully interpreted as anything other than ‘news’. On the other hand, if we chose topics = 100, they might be so specific that we can’t see the useful connections between topics. For a newspaper example, we might say that 20 – 30 topics is appropriate, but when we don’t really know the appropriate number (or even what we mean by ‘appropriate’), things can get more tricky.
Two quick examples:


Our goal, in generating in interpreting topic models, is to both try and understand what the themes are that animate Canadians’ conversations about Canada Reads and to see how our picture of that conversation changes when we alter the number of topics. We see this from these two examples.
In the 10-topic model we see that the topics generally group according to the authors and celebrities being discussed. There is a Mark Sakomoto topic, a Jully Black topic, etc. We also see a number of positive affect terms peppered throughout the topics: “amazing,” “discussed,” “favourite,” “hope”, “excited”, “love,” “happy,” “congratulations,” etc. As we’ve delved into our Twitter data we’ve noticed a great deal of positive feelings towards Canada Reads, Canadian literature, and the link between national identity and literary discourse more generally. We’re very interested in this apparent positivity and will be writing more on in it in the future.
In the 25-topic model we see a more complex picture of the discourse. An entire topic is dedicated to Jully Black’s defence of Cherie Dimaline’s The Marrow Thieves, signalled by terms like “defend,” “discuss” “Marrow Thieves,” “listening,” “defending,” “best,” and important. This is likely in response to the disagreement between Jeanne Beker and Jully Black during the 2018 broadcast. In subsequent posts we’ll delve into more details about the actual topic modeling data in order to indicate what it can tell us about what people are saying about Canadian literature online.
Further Reading

Canada Reads 2020: Facebook Group Author Q&As
Every week in April, the CBC’s Canada Reads Facebook group hosted Q&A sessions with each of the authors of Canada Reads 2020.